
Por D. Ángel Rodriguez Villodres
Hoy en día, y al contrario de lo que ocurre con otras enfermedades graves causadas por virus, es raro encontrar una persona que no sepa medianamente lo que es el VIH o la enfermedad que ocasiona (SIDA); quizás sea porque nos afecta de lleno en nuestro bonito primer mundo. Pero también, desgraciadamente, una parte de estas personas sienten un tremendo rechazo hacia los afectados por este virus, aún cuando hay suficiente información accesible sobre el mismo que desmiente muchos de los tópicos que aún persisten en la población.
Desde hace tiempo investigadores de todo el mundo están realizando un esfuerzo inmenso para tratar de comprender los secretos moleculares que guarda, y pese a que se ha avanzado mucho en el control de la infección, aún no se ha conseguido dar con la clave para acabar con esta epidemia de distribución mundial.
Un aspecto importante del VIH es su genoma, en el cual nos vamos a detener en los siguientes párrafos tratando de explicar las distintas partes que lo componen, así como las proteínas a las que da lugar, las cuales permiten que finalmente nuevas partículas víricas salgan de la célula hospedadora; sin embargo antes de meternos de lleno en este tema vamos a hacer una pequeña introducción para situar al lector.
El VIH o virus de la inmunodeficiencia humana es un virus perteneciente a la familia Retroviridae, subfamilia Orthoretrovirinae y al género Lentivirus. Como todos sabréis, es el causante del SIDA o síndrome de inmunodeficiencia adquirida.
Se conocen dos tipos de VIH genética y antigénicamente diferentes, denominados VIH-1 y VIH-2. El VIH-1 es el agente responsable de la epidemia mundial de SIDA, mientras que el VIH-2 es un virus endémico del África Oriental y es raro encontrarlo fuera de esta región. Los genomas de estos dos tipos de virus tienen una similitud de sólo el 40-50%; sin embargo ocasionan una enfermedad clínicamente indistinguible, aunque el VIH-2 presenta una patogenicidad más baja y una progresión más lenta a SIDA, por lo que la enfermedad es menos agresiva que la producida por el VIH-1. En esta ocasión, debido a su mayor importancia y para no complicar más las cosas, sólo vamos a hacer referencia al genoma y a la estructura del VIH-1.
Cada virión presenta, a grandes rasgos, una estructura esférica cuya parte externa está rodeada por una envuelta lipídica procedente de la membrana plasmática de la célula hospedadora. En el interior de esta membrana se encuentra una matriz que separa la envuelta de la cápside, la cual es de tipo cilíndrico-cónico y contiene en su interior el genoma vírico (ARN monocatenario diploide de polaridad positiva) junto con varias enzimas, entre las que se encuentra la transcriptasa inversa. Vamos a ver una imagen estructural del VIH de forma que, más adelante, cuando se expliquen los distintos productos génicos poder tener una mejor visión de la implicación de cada uno en la estructura final del virus:
Como acabamos de ver, el virión del VIH contiene en su interior dos copias de ARNmc de polaridad positiva. ¿Esto qué quiere decir? La polaridad positiva del ARN vírico refleja que ésta es igual a la del ARN mensajero, es decir, aquel ARN que se obtiene al transcribir el ADN y a partir del cual se producen las proteínas por traducción. En el caso contrario se hablaría de polaridad negativa. De esta forma, se puede deducir que un virus con ARNmc de polaridad positiva podrá usar ésta cadena como un ARNm desde donde se producirán las proteínas víricas directamente. ¿Ocurre esto en el VIH? Pues no, los retrovirus (entre los que se incluye el VIH), a pesar de tener este tipo de ARN no pueden utilizarlo directamente como ARNm, sino que necesitan un paso intermedio en el cual, a partir del ARN, se obtiene una molécula de ADN bicatenario (ADNbc), denominada provirus, que se integra en el genoma de la célula hospedadora y a partir de la cual se producen las proteínas víricas previo paso por ARNm. Como podemos ver este proceso rompe con el dogma central de la biología molecular en el sentido de que permite la producción de ADN a partir de ARN, hecho por lo cual se denomina transcripción inversa o retrotranscripción y está a cargo de una enzima llamada transcriptasa inversa o retrotranscriptasa; pero todo este fascinante proceso se explicará de forma detallada en una futura entrada.
En ésta ocasión vamos a describir las distintas partes en las que se divide el ARN vírico, así como el papel que tiene cada una de estas en la estructura final del virión. Cabe decir que aunque normalmente se nos presenta esta molécula como una estructura lineal, lo cierto es que la verdadera estructura secundaria dista mucho de ser así, sino que más bien está formada por una serie de bucles y horquillas donde se encuentran las diferentes regiones. Pero aún falta bastante por saber y existe una exhaustiva investigación en este campo, por lo que intentaré exponer aquí de forma entendible la organización del genoma vírico sin entrar demasiado en la arquitectura molecular del mismo.
Si observamos los extremos en la imagen siguiente, cada molécula de ARN vírico presenta un Cap en 5’ y una cola de poli-A en el extremo 3’.

En el extremo 5’, justo tras el Cap, nos encontramos la región 5’-UTR cuya estructura secundaria consiste en una serie de horquillas conectadas entre sí como son:
- Región de transactivación (TAR): juega un papel esencial en la activación transcripcional mediada por la proteína Tat.
- Señal de poliadenilación (polyA): como su propio nombre indica, esta región contiene la señal de poliadenilación AAUAAA, la cual también se encuentra cerca del extremo 3’. Aunque se sabe que la señal de poliadenilación localizada en 3’ funciona en la maduración del mRNA, no se sabe mucho acerca de la función de la misma señal localizada en 5’.
- U5: contiene una secuencia ATT necesaria para la integración del genoma vírico en el ADN de la célula hospedadora y para el empaquetamiento del genoma del virus.
- Sitio PBS: es crítico para la replicación ya que sirve como sitio de unión para un tRNALys celular, el cebador para la transcripción inversa, y además sirve como elemento regulador que afecta a la iniciación de la misma.
- Sitio de inicio de la dimerización (DIS): actúa en la dimerización de las dos moléculas de RNA que finalmente formarán parte del virión.
- SD (splice donor): parece que juega un rol importante en el splicing de los mRNA víricos.
- Ψ: se piensa que esta secuencia es la que actúa como señal para el empaquetamiento del genoma del virus, aunque parece que no es la única responsable de este proceso.
 Si nos vamos al otro extremo del ARN vírico, nos encontramos la región 3’-UTR la cual está caracterizada por presentar una cola de poliadenilación (poli-A), una región U3 y una secuencia denominada ppt. La región U3 al igual que la U5 también contiene un sitio ATT, mientras que el sitio ppt es una región de polipurinas compuesta por 9 nucleótidos que actúan como cebadores para la síntesis de la cadena positiva de ADN en la transcripción inversa.
Si nos vamos al otro extremo del ARN vírico, nos encontramos la región 3’-UTR la cual está caracterizada por presentar una cola de poliadenilación (poli-A), una región U3 y una secuencia denominada ppt. La región U3 al igual que la U5 también contiene un sitio ATT, mientras que el sitio ppt es una región de polipurinas compuesta por 9 nucleótidos que actúan como cebadores para la síntesis de la cadena positiva de ADN en la transcripción inversa.
Tanto el 5’-UTR como el 3’-UTR son regiones no codificantes del genoma vírico. ¿Esto qué quiere decir? Pues que estas secuencias no son “leídas” por los ribosomas y por tanto no se traducen a ningún tipo de proteína. ¿Eso implica que no sean importantes? Al contrario, estas regiones contienen motivos regulatorios que son cruciales para que prácticamente todo el ciclo replicativo del virus se lleve a cabo de forma correcta. Entre las distintas funciones que llevan a cabo están: activar la transcripción, iniciar la transcripción inversa, facilitar la dimerización del genoma, empaquetamiento del virus, interaccionar con proteínas virales y del hospedador, etc.
Una vez descritos los dos extremos del ARN vírico, y antes de pasar a las secuencias codificantes del genoma, creo que es oportuno hablar aquí de la transcripción inversa en el sentido de los cambios que se producen en los extremos de la molécula de ADN generada por este proceso.
La nueva molécula de ADN obtenida por acción de la transcriptasa inversa, además de ser de doble cadena, contiene en sus extremos lo que se denominan LTR o repeticiones largas terminales. Estas secuencias se producen en el proceso de retrotranscripción y son claves, primero para la integración del ADN vírico en el genoma de la célula hospedadora, y luego para la transcripción correcta del mismo. Cada LTR está dividida en 3 zonas (U3, R y U5) tal como se puede ver en la imagen siguiente:


Para finalizar me gustaría decir que, como suele pasar en estos casos, aún no se conoce en su totalidad la arquitectura genómica del VIH, así como tampoco algunas de las funciones que llevan a cabo las proteínas aquí descritas; incluso a veces hay contradicciones entre los propios investigadores, lo que hace aún más difícil la tarea de intentar explicar este tema de una forma clara. Sin embargo, y a pesar de todo esto, también hay que recalcar que no son pocos los avances en este campo, ni lo son tampoco los esfuerzos realizados en la lucha contra este temido, pero apasionante virus.
REFERENCIAS
- Bell NM, Lever AML (2013). HIV Gag polyprotein: processing and early viral particle assembly. Trends in Microbiology. 21 (3): 136-142
- Delgado R (2011). Características virológicas del VIH. Enf Infecc Microbio Clin. 29(1):58-65
- Lu K, Heng X, Summers MF (2011). Structural Determinants and Mechanism of HIV-1 Genome Packaging. J. Mol. Biol 410: 609-633
- Watts JM, Dang KK, Gorelick RJ, Leonard CW, Bess JW, Swanstrom R, Burch CL, Weeks KM (2009). Architecture and secondary structure of an entire HIV-1 RNA genome. Nature 460: 711-716.
Desde hace tiempo investigadores de todo el mundo están realizando un esfuerzo inmenso para tratar de comprender los secretos moleculares que guarda, y pese a que se ha avanzado mucho en el control de la infección, aún no se ha conseguido dar con la clave para acabar con esta epidemia de distribución mundial.
Un aspecto importante del VIH es su genoma, en el cual nos vamos a detener en los siguientes párrafos tratando de explicar las distintas partes que lo componen, así como las proteínas a las que da lugar, las cuales permiten que finalmente nuevas partículas víricas salgan de la célula hospedadora; sin embargo antes de meternos de lleno en este tema vamos a hacer una pequeña introducción para situar al lector.
El VIH o virus de la inmunodeficiencia humana es un virus perteneciente a la familia Retroviridae, subfamilia Orthoretrovirinae y al género Lentivirus. Como todos sabréis, es el causante del SIDA o síndrome de inmunodeficiencia adquirida.
Se conocen dos tipos de VIH genética y antigénicamente diferentes, denominados VIH-1 y VIH-2. El VIH-1 es el agente responsable de la epidemia mundial de SIDA, mientras que el VIH-2 es un virus endémico del África Oriental y es raro encontrarlo fuera de esta región. Los genomas de estos dos tipos de virus tienen una similitud de sólo el 40-50%; sin embargo ocasionan una enfermedad clínicamente indistinguible, aunque el VIH-2 presenta una patogenicidad más baja y una progresión más lenta a SIDA, por lo que la enfermedad es menos agresiva que la producida por el VIH-1. En esta ocasión, debido a su mayor importancia y para no complicar más las cosas, sólo vamos a hacer referencia al genoma y a la estructura del VIH-1.
Cada virión presenta, a grandes rasgos, una estructura esférica cuya parte externa está rodeada por una envuelta lipídica procedente de la membrana plasmática de la célula hospedadora. En el interior de esta membrana se encuentra una matriz que separa la envuelta de la cápside, la cual es de tipo cilíndrico-cónico y contiene en su interior el genoma vírico (ARN monocatenario diploide de polaridad positiva) junto con varias enzimas, entre las que se encuentra la transcriptasa inversa. Vamos a ver una imagen estructural del VIH de forma que, más adelante, cuando se expliquen los distintos productos génicos poder tener una mejor visión de la implicación de cada uno en la estructura final del virus:
 |
| Imagen 1. Estructura del VIH. Vía: wikimedia |
En ésta ocasión vamos a describir las distintas partes en las que se divide el ARN vírico, así como el papel que tiene cada una de estas en la estructura final del virión. Cabe decir que aunque normalmente se nos presenta esta molécula como una estructura lineal, lo cierto es que la verdadera estructura secundaria dista mucho de ser así, sino que más bien está formada por una serie de bucles y horquillas donde se encuentran las diferentes regiones. Pero aún falta bastante por saber y existe una exhaustiva investigación en este campo, por lo que intentaré exponer aquí de forma entendible la organización del genoma vírico sin entrar demasiado en la arquitectura molecular del mismo.
Si observamos los extremos en la imagen siguiente, cada molécula de ARN vírico presenta un Cap en 5’ y una cola de poli-A en el extremo 3’.

En el extremo 5’, justo tras el Cap, nos encontramos la región 5’-UTR cuya estructura secundaria consiste en una serie de horquillas conectadas entre sí como son:
- Región de transactivación (TAR): juega un papel esencial en la activación transcripcional mediada por la proteína Tat.
- Señal de poliadenilación (polyA): como su propio nombre indica, esta región contiene la señal de poliadenilación AAUAAA, la cual también se encuentra cerca del extremo 3’. Aunque se sabe que la señal de poliadenilación localizada en 3’ funciona en la maduración del mRNA, no se sabe mucho acerca de la función de la misma señal localizada en 5’.
- U5: contiene una secuencia ATT necesaria para la integración del genoma vírico en el ADN de la célula hospedadora y para el empaquetamiento del genoma del virus.
- Sitio PBS: es crítico para la replicación ya que sirve como sitio de unión para un tRNALys celular, el cebador para la transcripción inversa, y además sirve como elemento regulador que afecta a la iniciación de la misma.
- Sitio de inicio de la dimerización (DIS): actúa en la dimerización de las dos moléculas de RNA que finalmente formarán parte del virión.
- SD (splice donor): parece que juega un rol importante en el splicing de los mRNA víricos.
- Ψ: se piensa que esta secuencia es la que actúa como señal para el empaquetamiento del genoma del virus, aunque parece que no es la única responsable de este proceso.

Tanto el 5’-UTR como el 3’-UTR son regiones no codificantes del genoma vírico. ¿Esto qué quiere decir? Pues que estas secuencias no son “leídas” por los ribosomas y por tanto no se traducen a ningún tipo de proteína. ¿Eso implica que no sean importantes? Al contrario, estas regiones contienen motivos regulatorios que son cruciales para que prácticamente todo el ciclo replicativo del virus se lleve a cabo de forma correcta. Entre las distintas funciones que llevan a cabo están: activar la transcripción, iniciar la transcripción inversa, facilitar la dimerización del genoma, empaquetamiento del virus, interaccionar con proteínas virales y del hospedador, etc.
Una vez descritos los dos extremos del ARN vírico, y antes de pasar a las secuencias codificantes del genoma, creo que es oportuno hablar aquí de la transcripción inversa en el sentido de los cambios que se producen en los extremos de la molécula de ADN generada por este proceso.
La nueva molécula de ADN obtenida por acción de la transcriptasa inversa, además de ser de doble cadena, contiene en sus extremos lo que se denominan LTR o repeticiones largas terminales. Estas secuencias se producen en el proceso de retrotranscripción y son claves, primero para la integración del ADN vírico en el genoma de la célula hospedadora, y luego para la transcripción correcta del mismo. Cada LTR está dividida en 3 zonas (U3, R y U5) tal como se puede ver en la imagen siguiente:

La generación de estos LTR tiene lugar tiene lugar en el proceso de transcripción inversa como ya hemos dicho anteriormente y es uno de los motivos de por qué el DNA es algo más grande que el RNA original. La importancia de estas regiones así como la forma en la que se generan se explicará detalladamente en un próximo capítulo sobre este apasionante tema.
Ahora que ya hemos pasado por los extremos del genoma nos vamos a ir a la región central, donde se encuentran las secuencias codificantes y en las que podemos encontrar tres genes principales, comunes a todos los retrovirus:
- gag: codifica una poliproteína Gag (o antígeno específico de grupo) de 55 kDa (p55) que se escinde por la proteasa viral para formar las siguientes proteínas estructurales
o La proteína de matriz p17 (MA) que se encuentra anclada al interior de la membrana gracias a una miristilación previa en su extremo amino-terminal.
o La proteína de la cápside p24 (CA) que, como su propio nombre indica, es la que, mediante polimerización, da lugar a la cápside cilíndrica-cónica del virus.
o Péptido espaciador 1, p2 (SP1) compuesto sólo por 14 aminoácidos, participa en el ensamblaje de CA para formar la cápside.
o La proteína de la nucleocápside p7 (NC) cuya función principal (o más conocida) es reconocer el ARN del virus y formar la nucleocápside; sin embargo también se une de modo específico a la señal de empaquetamiento ψ y realiza una serie de funciones distintas sumamente importantes.
o Péptido espaciador 2, p1 (SP2) de 16 aminoácidos, el cual parece que podría ser importante para la incorporación de Gag y Pol en el virión.
o La proteína p6 que junto con la proteína p7 (NC) forman la nucleocápside, y además, por otro lado, se une a una proteína accesoria del virus (Vpr) conduciendo la incorporación de la misma al interior de los viriones.
- pol: las proteínas que da lugar este gen se producen a partir de una proteína precursora llamada Gag-Pol (p160), la cual se genera por un cambio de lectura ribosomal, provocado por un motivo específico del ARN en la región distal del gen gag. A partir de este precursor se obtienen:
o Proteasa (p10): es una proteína dimérica que actúa escindiendo los precursores poliproteicos Gag y Gag-Pol durante la maduración del virus.
o Transcriptasa inversa: es la polimerasa vírica, cuya forma funcional predominante es un heterodímero de p65 y p50. Actúa generando una molécula de ADN bicatenaria a partir del ARN monocatenario original del virus.
o Integrasa (p31): esta proteína es la que actúa en la inserción del ADN vírico en el ADN de la célula hospedadora infectada.
- env: da lugar a una proteína precursora de 160 KDa (gp160) la cual es sintetizada en el retículo endoplasmático para posteriormente ser transportada al aparato de Golgi, donde será glicosilada antes de sufrir una escisión por una proteasa celular, para dar lugar a dos glicoproteínas que se encuentran unidas de forma no covalente formando las espículas, que se proyectan en la superficie externa del virus y que son esenciales para el reconocimiento y la infección de la célula hospedadora:
o gp120 (SU): forma un heterotrímero que se aloja en la zona más externa de la membrana
o gp41 (TM): forma un tronco transmembrana de 3 moléculas de esta proteína al que se unen de forma no covalente las tres moléculas de gp120 para formar una espícula de la envuelta vírica.
Además de estos tres genes principales, común a todos los retrovirus, el VIH presenta una serie de genes adicionales que codifican proteínas reguladoras como son:
- Tat: este gen codifica la proteína Tat, un activador de la transcripción. La proteína Tat se une al ARN vírico (a diferencia de los factores de transcripción convencionales) en una estructura en horquilla en la región 5’ del genoma conocida como TAR y que hemos visto anteriormente. La unión de esta proteína activa la transcripción de los genes del VIH unas 1000 veces más.
- Rev: codifica una proteína denominada Rev, que se une de forma específica al ARN vírico y favorece la transición de la expresión génica del VIH de la fase temprana a la fase tardía. Rev se une a una estructura secundaria del ARN denominada RRE (elemento de respuesta a Rev) que se encuentra dentro de la región codificante del gen env.
Aparte de estas dos proteínas reguladoras tenemos una serie de genes que codifican proteínas accesorias, las cuales no son imprescindibles para la replicación vírica in vitro, pero representan factores críticos para la virulencia in vivo. La mayoría de estas proteínas tienen múltiples funciones:
- Nef: codifica una proteína temprana miristilada del virus, cuyo único exón está localizado cerca del extremo 3’. Entre sus funciones destacan:
o La disminución de la tasa de expresión del receptor CD4 de los linfocitos T.
o Interferencia en la activación de linfocitos T, de forma que parece que puede ejercer distintos efectos sobre la activación de estas células según el contexto de su expresión.
o Aumento de la infectividad de los viriones.
o Favorece la progresión hacia SIDA.
- Vif: codifica un polipéptido de 23 KDa con las siguientes funciones:
o Altera la actividad de la proteína antivírica humana APOBEC3G, una citidina desaminasa con capacidad de provocar mutaciones en el genoma vírico.
o Aumenta la infectividad del VIH entre 100 y 1000 veces
- Vpu: produce una fosfoproteína integral de membrana cuyo gen solapa en su extremo 3’ con el gen env. De esta forma Vpu y Env se expresan a partir del mismo ARNm. Sin embargo la proteína Vpu se produce en concentraciones mucho más bajas que la proteína Env. Se piensa que esto es debido a un mecanismo conocido como “leaky scanning” donde se traducen más proteínas en función de que el contexto alrededor del codón de iniciación de la proteína sea más o menos favorable para la lectura a cargo de los ribosomas. De esta forma, el codón de iniciación de Env es más favorable que el de Vpu, lo que explica la diferencia en la concentración de ambas proteínas. Las dos principales funciones de Vpu son:
o Regulación negativa del receptor CD4, de forma que reduce la cantidad de las moléculas de este receptor que se expresan en la superficie celular.
o Facilita el ensamblaje y favorece la liberación de los viriones de la superficie celular.
- Vpr: codifica una proteína que se incorpora al interior de las partículas víricas mediante interacciones específicas con el precursor Gag (p55) y con una gran participación de la proteína p6. Entre sus funciones destacan dos:
o Parece acelerar el proceso de replicación vírica, actuando como un factor de transporte del ADN vírico al núcleo, facilitando así la localización del complejo de preintegración.
o Produce un bloqueo de la división celular.
En la siguiente imagen podéis ver la disposición de los genes que acabamos de ver así como las distintas proteínas a las que finalmente dan lugar:
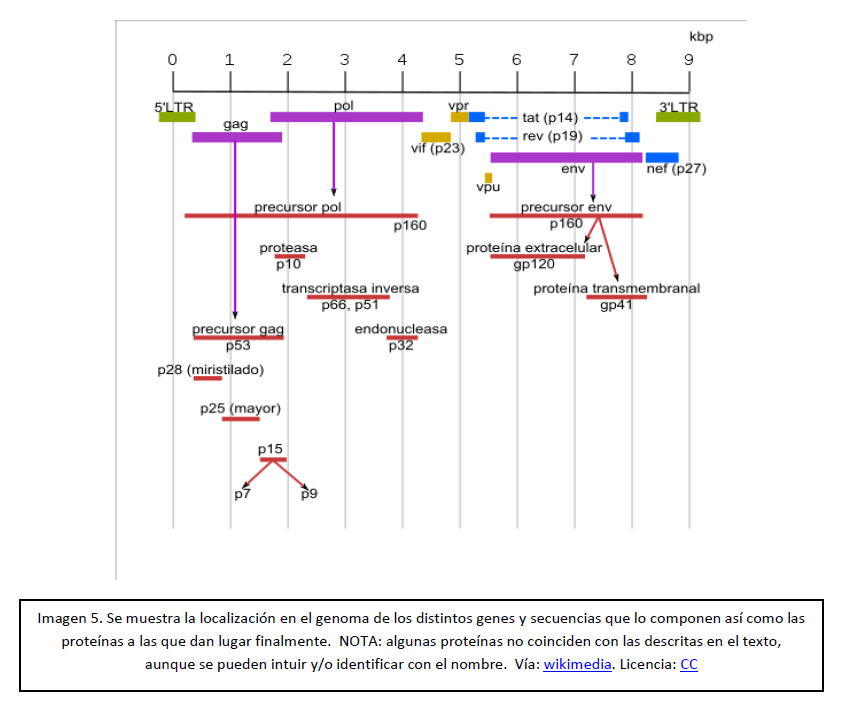
Para finalizar me gustaría decir que, como suele pasar en estos casos, aún no se conoce en su totalidad la arquitectura genómica del VIH, así como tampoco algunas de las funciones que llevan a cabo las proteínas aquí descritas; incluso a veces hay contradicciones entre los propios investigadores, lo que hace aún más difícil la tarea de intentar explicar este tema de una forma clara. Sin embargo, y a pesar de todo esto, también hay que recalcar que no son pocos los avances en este campo, ni lo son tampoco los esfuerzos realizados en la lucha contra este temido, pero apasionante virus.
REFERENCIAS
- Bell NM, Lever AML (2013). HIV Gag polyprotein: processing and early viral particle assembly. Trends in Microbiology. 21 (3): 136-142
- Delgado R (2011). Características virológicas del VIH. Enf Infecc Microbio Clin. 29(1):58-65
- Lu K, Heng X, Summers MF (2011). Structural Determinants and Mechanism of HIV-1 Genome Packaging. J. Mol. Biol 410: 609-633
- Watts JM, Dang KK, Gorelick RJ, Leonard CW, Bess JW, Swanstrom R, Burch CL, Weeks KM (2009). Architecture and secondary structure of an entire HIV-1 RNA genome. Nature 460: 711-716.
Soy del Reino Unido. Doy gracias a un gran médico que me ayudó a salir de mi enfermedad. Estaba muy enfermo. Doy gracias a Dios que usó a este hombre para ayudar, comenzó cuando viajé a Florida para visitar allí. Conocí a una señora que no sabía que es seropositiva Me gusta mucho la mujer porque era hermosa Siempre la veo cada vez que cierro los ojos Fui a decirle cómo me sentía por ella, pero no sé si ella sabe que era VIH. Me fui a la cama con ella. Me puse en contacto con el virus también cuando llegué a casa por un mes, mi médico vino a revisarme y descubrió que tenía VIH, estaba conmocionado y me dijo que estaba tan confundido y tan sorprendido de escuchar que estaba tomando un medicamento contra el VIH para curarlo. bueno, 2 años, decidí buscar curarlos. Encontré esta publicación en Internet. Lo contacté para pedir ayuda ... bueno, DR. Rico, demostrando ser un gran hombre y él me curó ... Según él, dijo que el poder de sus dioses es bueno. Le agradezco a Dios que haya regresado nuevamente si necesita cura para su VIH ... aún puede comunicarse con él o con su correo electrónico o número. Le prometo que es 100% él cura cualquier virus como T-VIRUS HIV AID ROTA-VIRUS, SMALLPOX, HEPATITIS B si tiene este virus o amigo no familiar, contáctelo ahora wealthylovespell@gmail.com o agréguelo en WhatsApp +2348105150446
ResponderEliminarI can’t believe this is really true I never believe there is cure to this hsv 2 because all the hospital have told me there is no cure to it, few months ago I saw this man email DR.AZIEGBE on internet from a testimony share by someone who he help with his herbal cure I contact his email and ask for his help also, that is how he inform me about the cure process and this man sent me a herbal medicine which I took according to the way he instructed for 2 week I can’t believe when I go for test my result come out negative i am so happy to share this to the world there is real cure to herpes you can also contact DR.AZIEGBE through his email now DRAZIEGBE1SPELLHOME@GMAIL. COM and also WhatsApp him +2349035465208. or my assistant my email: JAMESAVA0001@GMAIL. COM... He also have herbs medicine to cured the following diseases;
EliminarDiabetes, Lupus, HPV, Gout, Hepatitis A,B, Infertility, HIV/AIDS, CANCER, WART
Mi nombre es Subham Kumar Khalid de Nawada India, después de que el Dr. White me curara del VIH, me encargué de informar a las personas que creen que los virus y otras enfermedades crónicas no tienen cura. Después de leer el testimonio de cierta Carolina, decidí intentarlo, pero hoy soy un testigo saliente y por el resto de mi vida estaré agradecido con este sanador agradecido y poderoso. Después de leer sobre él en un blog con su correo electrónico claramente indicado como: DRWHITETHEHIVHEALER@GMAIL.COM y whatsapp: 2349091844595, me pregunté por qué el gobierno en todos los niveles no se unirá para expandir y promover esta cura incluso cuando es de Nigeria y un nación negra. Al igual que tú, tuve mis dudas y reservas, pero luego decidí tomar mi destino en mis manos, incluso cuando los médicos dijeron que era imposible al contactarlo. Mira, mi larga tristeza se convirtió en alegría después de solo unos días de tomar sus hierbas. Si de verdad quieres deshacerte de tu enfermedad, te recomiendo sinceramente que te comuniques con él.
EliminarHe oído hablar de personas que hablan de milagros y magia, he visto avances científicos y se han puesto en uso medicinas naturales, he oído hablar de profetas religiosos que hablan de curaciones milagrosas, pero les digo esto con toda sinceridad que nunca he sido un beneficiario. de cualquiera de estos hasta que tuve un encuentro con Doc. White (DRWHITETHEHIVHEALER@GMAIL.COM o WATSAPP OO2349O91844595) a través de quien llegué a saber que verdaderamente el Cielo ha curado tanto a las hierbas. Tenía VIH combinado con hepatitis, era como el final del camino para mí, pero de alguna manera leí sobre Doc. White en un blog y le escribí con pocas esperanzas de curarse. Me pidió que primero pagara por la cura del VIH, que me curara antes de comprar la cura para la hepatitis, lo cual hice, y resulta ser la mejor decisión de toda mi existencia, ya que he dado negativo en ambas dolencias mientras escribo. Quizás le interese saber que estas curas a base de hierbas me fueron enviadas a través del servicio de mensajería con una prescripción definida de uso y las obtuve en pocos días. Es importante que les informe antes de conocer al Doc. White He conocido a muchos imitadores que no hicieron nada más que agravar mi condición y después de curarme con el Dr. White, le he recomendado a innumerables personas directamente y en DRWHITETHEHIVHEALER@GMAIL.COM sobre diferentes enfermedades como el VPH, el cáncer, el herpes, la diabetes y eso siempre sale bien. No pierda la esperanza ahora.
EliminarArnold O. Vanella es mi nombre de nacimiento y vivo en el Reino Unido. Escríbeme en facebook o oarnold955@gmail.com. Debes vivir para cumplir tu sueño
Hola chicos, tengo un testimonio que compartir y tiene algo que ver con mi papá, cómo se curó de su diabetes y dolores severos en todas las articulaciones de su cuerpo por un doctor de hierbas africanas llamado Dr. UDO Mi nombre es Jeremy Ronald Rene, soy de la ciudad de Monte Plata aquí en República Dominicana, mi papá sufre de diabetes y dolores articulares severos por un par de años, mi mamá y yo probamos tantos medicamentos para asegurar que mi papá se recuperara, pero todos nuestros esfuerzos no sirvieron para nada. No produjo buenos resultados. Leí muchas críticas positivas sobre las medicinas naturales del Dr. UDO y cómo tantas personas se habían curado de varias enfermedades después de usarlas, así que le conté a mi mamá y contactamos al Dr. UDO y le conté la salud de mi papá después de explicarle todo sobre el Nos convencieron y decidimos pedir los medicamentos. Él preparó los medicamentos y nos los envió a través de DHL después de un par de días que ordenamos. No esperaba nada extraordinario, pero dos días después del inicio del tratamiento mi papá se sintió notablemente mejor, estaba más activo, no le dolían todas las articulaciones, el dolor desapareció por completo y también se evaluó la diabetes. Sin dolor en absoluto. Estoy feliz de que ahora pueda hacer las tareas de la casa. Por favor, recomiendo a todos que lo contacten para una cura permanente para el VIH, cáncer, quistes ováricos, asma, hepatitis crónica, artritis, neumonía, sífilis, herpes, VPH , parkinson, infertilidad, insuficiencia renal, enfermedad cardíaca, verrugas genitales, epilepsia, erección débil, disfunción eréctil, vaginosis bacteriana, VIH1 y VIH2, diabetes tipo1, herpes tipo1, endometriosis, hemodiálisis, hipoglucemia, colecistitis aguda, cáncer anal, angioedema, intestino cáncer candidasis, tinnititis, todo tipo de infecciones, tuberculosis, rinitis, tumor de cáncer de cerebro, cáncer de mama, fibromas, agrandamiento de pene, mal aliento. Puedes contactarlo a través de su correo electrónico o número de whatsapp. Número de Whatsapp .......... + 234-805-107-5165. Y aqui esta su
Eliminardirección de correo electrónico ......... DRUDOAZIBAHIVHEALINGCENTRE@GMAIL.COM. Es un hombre muy sincero, sus medicinas funcionan de manera sorprendente y eficaz, soy un testigo vivo
Qué gran testimonio me gustaría que todos leyeran y siguieran las instrucciones para curarse de HSV1 y 2. Me diagnosticaron VHS1 y el 2 de marzo de este año y he estado tomando pastillas para prevenir el brote. Nunca dejo de buscar una cura porque creo firmemente que hay algo en algún lugar que puede deshacerse de ella por completo y en agosto de este año, repasé algunos comentarios en Youtube sobre la cura a base de hierbas del Dr. Osato y muchas personas comentaron que tenía la hierbas que pueden eliminar el herpes por completo. Estaba emocionado y me comuniqué con el Dr. Osato y ordené la cura para mí y él me la envió a través de UPS y me dio instrucciones sobre cómo tomarla, que seguí correctamente y he aquí, fui a un chequeo después de dos semanas de tomar las hierbas y mi el resultado muestra NEGATIVO. Mi médico confirmó conmigo que estoy totalmente libre de HSV1 y 2. También puede ponerse en contacto con el Dr. Osato para obtener la cura a base de hierbas de él. Su correo electrónico es osatoherbalcure@gmail.com o WhatsApp él al +2347051705853. El Dr. Osato también tiene la cura para los siguientes virus / enfermedades VIH, VPH, VHS1 y 2, DIABETES, CÁNCER de cualquier tipo, HERPES GENITALES, DOLOR FRÍO ECT. Su sitio web es osatoherbalcure.wordpress.com
EliminarMeu nome é ESTEBAN AMARO, sou da cidade de LOS-VILO aqui no chile. Eu fiz uma tomografia computadorizada em agosto de 2009, constatando que eu tinha fibrose pulmonar idiopática. Meus primeiros sintomas foram tosse e falta de ar. Eu estava tomando prednisona e inaladores. Meu nível de oxigênio no sangue era 50 e eu estava com muita falta de ar, mal conseguia respirar. Passei por uma reabilitação cardiopulmonar. Ajudou, mas não muito antes de todos os sintomas graves retornarem. Em dezembro do ano passado, um amigo da família nos contou sobre um homem chamado Dr. Udo Aziba, e eles disseram que ele cura muitas doenças. Disseram-me para tentar contatá-lo para que ele pudesse curar minha doença permanentemente.Eu procurei por o contato dele e entrei em contato com ele, eu disse a ele meus problemas de saúde e ele disse que pode me curar, ele preparou algumas ervas naturais e me enviou através da transportadora Fedex e eu recebi os medicamentos após alguns dias e imediatamente iniciei o tratamento, i tomei os medicamentos por um período de 30 dias, estou feliz em relatar que este tratamento reverteu efetivamente minha fibrose pulmonar idiopática e sintomas. Estou de pé novamente, agora caminho diariamente e isso me tornou capaz de passear com meus dois cães novamente sem falta de ar ou perda repentina de energia. Meu nível de atividade subiu novamente. Minha gratidão a Deus Todo-Poderoso por usar um fitoterapeuta chamado Dr. Udo Aziba para salvar minha vida desta terrível doença que tenho lutado há anos. Compartilhar meu testemunho e vivenciei aqui está longe de permitir que as pessoas saibam que os medicamentos naturais podem ser uma opção melhor em algumas doenças. os medicamentos naturais não têm efeitos colaterais. Eles são 100 por cento puramente naturais. Estou usando esse meio para chamar a atenção de pessoas que vivem com as seguintes doenças: HIV, Câncer, Hepatite B , Cistos ovarianos, Pneumonia, Diabetes, Sífilis, Candidíase, Dor de Garganta, Parkinson, Herpes, HPV, Verrugas Genitais, Asma, Fibroide, Ereção fraca, Problemas respiratórios, Endometriose, Infertilidade em mulheres, Disfunção Erétil, Dor de garganta, Doença cardíaca, Rim doença, e tantas outras que não mencionei. Entre em contato com o Dr. Udo Aziba para uma cura completa para essas doenças. Este é o Dr. Udo WhATSAPP Número 00234-805-107-5165. e aqui está também seu endereço de e-mail DRUDOAZIBAHIVHEALINGCENTRE@GMAIL.COM.
Eliminariled. Llegué a un punto en el que me acerqué a una enfermera que suele venir a mi casa a tratarme todas las mañanas y todas las noches después del tratamiento mi condición sigue siendo la misma Un día fiel fui al hospital para mi chequeo habitual el 12 de septiembre 2020 y estaba esperando mi turno cuando un hombre negro de África llamado Sr.Johnson entró y me vio, se acercó a mí y me saludó como si supiéramos antes que yo no supiera que Dios lo usará para curarme. Creo que sufre de diabetes y le dije que sí y le expliqué cómo he estado sufriendo esta enfermedad durante años y él dijo que lo derivaré a un herbolario que lo curará en un período de 3 semanas de tratamiento. suena a broma, dijo que sí, el nombre del médico es DR UDO, curó a mi hermano mayor de la diabetes tipo 1, fue entonces cuando supe que hablaba en serio, pedí contacto con el médico y me lo dio, cuando Llegué a casa, lo llamé y le dije mi nombre y mis problemas y él dijo que estaba bien, que me dijo todos los pasos necesarios y me aseguro de cumplir con todos los pasos.Él pudo preparar los medicamentos y enviármelos después de unos días de contactarlo.Me explicó cómo tomaría los medicamentos, tomé el medicinas estrictamente siguiendo sus instrucciones y he aquí que ya me sentía bien antes de que terminaran los días del tratamiento y hasta la fecha no sentía ninguna enfermedad, las hierbas medicinales naturales erradicaron por completo no solo la diabetes, incluidas otras pequeñas enfermedades en mi cuerpo. es que no sé cómo agradecer al Dr. UDO. Él ha hecho lo que tantos médicos no pudieron hacer durante años. Realmente no puedo agradecerle lo suficiente, pero Dios Todopoderoso lo bendecirá. Me gustaría dejar de contactar a DR UDO. para personas que viven con VIH, CÁNCER, HEPATITIS B, DIABETES, CÁNCER, SÍFILIS, FALLA RENAL, GARGANTA, GARGANTA SECA, CANDIDIASIS y muchos más para comunicarse con el DR UDO para curas completas. .COM y el número de whatsAPP ... + 2348051075165.
EliminarEl Dr. ISE realmente ha demostrado al mundo que es real y genuino y ha utilizado su hazaña a base de hierbas para salvar a muchas personas de HERPES, VIH, VPH, ÚLTIMOS FRÍOS, CÁNCER, DIABETES, INFECCIONES VAGINALES, etc. Me diagnosticaron herpes y VPH en 2011 y he estado buscando y haciendo preguntas para ver si podía conseguir algo para curar el virus porque no creía lo que dicen los médicos de que aún no se ha encontrado una cura. Encontré un comentario en Youtube y la persona testificó cómo se curó de HSV2 después de usar la medicina herbal del Dr. ISE. Me comunico rápidamente con el Dr. ISE y le explico mi problema y él prepara el medicamento a base de hierbas y me lo envía y me da instrucciones sobre cómo usarlo y me dice que vaya a un chequeo después del uso, lo cual hice después de dos semanas de tomar el medicamento medicamento y mi resultado fue NEGATIVO .------- [- IVE '] Esperé otro mes y volví a probar que el resultado seguía siendo NEGATIVO y mi médico me dijo que estoy completamente libre de herpes y VPH. Estoy muy feliz y agradecido con el Dr. ISE por lo que ha hecho por mí y continuaré compartiendo esto para que la gente sepa que existe una cura para el herpes y el VPH. Puede ponerse en contacto con el Dr. ISE por correo electrónico a para obtener la cura de él.
Eliminarcureherbal633@gmail.com o
isespiritualspelltemple@gmail.com
El Dr. ISE realmente ha demostrado al mundo que es real y genuino y ha utilizado su hazaña a base de hierbas para salvar a muchas personas de HERPES, VIH, VPH, ÚLTIMOS FRÍOS, CÁNCER, DIABETES, INFECCIONES VAGINALES, etc. Me diagnosticaron herpes y VPH en 2011 y he estado buscando y haciendo preguntas para ver si podía conseguir algo para curar el virus porque no creía lo que dicen los médicos de que aún no se ha encontrado una cura. Encontré un comentario en Youtube y la persona testificó cómo se curó de HSV2 después de usar la medicina herbal del Dr. ISE. Me comunico rápidamente con el Dr. ISE y le explico mi problema y él prepara el medicamento a base de hierbas y me lo envía y me da instrucciones sobre cómo usarlo y me dice que vaya a un chequeo después del uso, lo cual hice después de dos semanas de tomar el medicamento medicamento y mi resultado fue NEGATIVO .------- [- IVE '] Esperé otro mes y volví a probar que el resultado seguía siendo NEGATIVO y mi médico me dijo que estoy completamente libre de herpes y VPH. Estoy muy feliz y agradecido con el Dr. ISE por lo que ha hecho por mí y continuaré compartiendo esto para que la gente sepa que existe una cura para el herpes y el VPH. Puede ponerse en contacto con el Dr. ISE por correo electrónico a para obtener la cura de él.
Eliminarcureherbal633@gmail.com o
isespiritualspelltemple@gmail.com
El Dr. ISE realmente ha demostrado al mundo que es real y genuino y ha utilizado su hazaña a base de hierbas para salvar a muchas personas de HERPES, VIH, VPH, ÚLTIMOS FRÍOS, CÁNCER, DIABETES, INFECCIONES VAGINALES, etc. Me diagnosticaron herpes y VPH en 2011 y he estado buscando y haciendo preguntas para ver si podía conseguir algo para curar el virus porque no creía lo que dicen los médicos de que aún no se ha encontrado una cura. Encontré un comentario en Youtube y la persona testificó cómo se curó de HSV2 después de usar la medicina herbal del Dr. ISE. Me comunico rápidamente con el Dr. ISE y le explico mi problema y él prepara el medicamento a base de hierbas y me lo envía y me da instrucciones sobre cómo usarlo y me dice que vaya a un chequeo después del uso, lo cual hice después de dos semanas de tomar el medicamento medicamento y mi resultado fue NEGATIVO .------- [- IVE '] Esperé otro mes y volví a probar que el resultado seguía siendo NEGATIVO y mi médico me dijo que estoy completamente libre de herpes y VPH. Estoy muy feliz y agradecido con el Dr. ISE por lo que ha hecho por mí y continuaré compartiendo esto para que la gente sepa que existe una cura para el herpes y el VPH. Puede ponerse en contacto con el Dr. ISE por correo electrónico a para obtener la cura de él.
Eliminarcureherbal633@gmail.com o
isespiritualspelltemple@gmail.com
El Dr. ISE realmente ha demostrado al mundo que es real y genuino y ha utilizado su hazaña a base de hierbas para salvar a muchas personas de HERPES, VIH, VPH, ÚLTIMOS FRÍOS, CÁNCER, DIABETES, INFECCIONES VAGINALES, etc. Me diagnosticaron herpes y VPH en 2011 y he estado buscando y haciendo preguntas para ver si podía conseguir algo para curar el virus porque no creía lo que dicen los médicos de que aún no se ha encontrado una cura. Encontré un comentario en Youtube y la persona testificó cómo se curó de HSV2 después de usar la medicina herbal del Dr. ISE. Me comunico rápidamente con el Dr. ISE y le explico mi problema y él prepara el medicamento a base de hierbas y me lo envía y me da instrucciones sobre cómo usarlo y me dice que vaya a un chequeo después del uso, lo cual hice después de dos semanas de tomar el medicamento medicamento y mi resultado fue NEGATIVO .------- [- IVE '] Esperé otro mes y volví a probar que el resultado seguía siendo NEGATIVO y mi médico me dijo que estoy completamente libre de herpes y VPH. Estoy muy feliz y agradecido con el Dr. ISE por lo que ha hecho por mí y continuaré compartiendo esto para que la gente sepa que existe una cura para el herpes y el VPH. Puede ponerse en contacto con el Dr. ISE por correo electrónico a para obtener la cura de él.
Eliminarcureherbal633@gmail.com o
isespiritualspelltemple@gmail.com
Se suponía que iba a dar este testimonio hace unas semanas pero mi agenda era muy apretada en el trabajo. Soy Leonor Martim, vivo en la ciudad de setúbal, portugal y trabajo en BNP Paribas Securities aquí en Almada setubal. Hace unos meses, mi esposo [martim] me contagió del VIH; estábamos tomando medicamentos antirretrovirus hasta el día en que mi amiga me aconsejó que dejara de hacerlo y buscara una forma natural de deshacerme del virus del VIH de una vez por todas. cura el virus, excepto los medicamentos naturales, así que le pregunté cómo conseguir un médico que me ayudara y ella llamó a su padre que está en otro país y le contó sobre la enfermedad del VIH, fue su padre quien nos envió el el número de teléfono del médico herbal, le envié un mensaje por whatsapp y él respondió después de unas horas y le dije cómo obtuve su número y mis razones para contactarlo, me hizo algunas preguntas después de eso, me dijo que puede curar el VIH y luego Estaba muy emocionado por la buena noticia. Le envío un poco de dinero para preparar los productos y enviárnoslos, lo que en realidad hizo después de 6 días. Él envía un papel que contiene las recetas sobre cómo tomaríamos los medicamentos, comenzamos a tomar los medicamentos según las recetas que nos envía y tomamos los medicamentos durante un período de 24 días y fuimos al hospital para una prueba. y me confirmaron negativo, no estaba satisfecho con el resultado, así que fui a otro hospital fuera de mi ciudad para realizar otra prueba y también me confirmaron VIH negativo. Mi esposo también fue a otro hospital y también se confirmó negativo. Honestamente hablando La alegría y la felicidad en mi hogar en este momento están más allá de la comprensión humana. Fui al lugar de trabajo y mostré el resultado de la prueba y me dijeron que reanudara el trabajo al día siguiente. Le ruego al mundo entero que me ayude a apreciar a dr udo por curarnos a mí y a mi esposo. El Dr. Udo me dijo que tiene curas para tantas enfermedades. Insto a cualquier persona con alguna enfermedad causada por el esturbón a que se conecte a dr udo para obtener una cura permanente por correo electrónico y whatsapp. whatsaPP ....... Número ... 234-805-107-5165. o envíele un correo electrónico a drudoazibahivhealingcentre@gmail.com.
EliminarNo me bastan las palabras para expresar lo agradecido que estoy estos días. Nunca quise revelar mi identidad, pero debo hacerlo para que quienes viven en la duda y el miedo puedan hacer sus necesidades y tomar decisiones. Quiero agradecer a este maravilloso médico, el Dr. ISE, por su amabilidad incondicional y su apoyo a los pacientes. Me diagnosticaron cáncer el 18 de enero de 2018. He estado en muchos lugares y probé varios tratamientos en vano, leí en las personas testimonios después de usar el Dr. ISE, Herbal, cómo se curaron de Diabetes, Dolores de estómago, Tumol, alergias corporales, VIH, HERPES, VPH, CÁNCER y muchas otras enfermedades e infecciones No estaba convencido porque he pasado mucha gente buscando buscando una cura y demasiado beneficio para mí y me escapé con mi poco dinero duramente ganado hasta que un amigo cercano me contó más sobre el Dr. Ise, cómo su tío, que sufría de VIH y el virus del herpes, se curó después de usar la medicina herbal del Dr. ISE, Inicialmente pensé que era una broma hasta que me ayudó a ordenar medicinas terapéuticas a base de hierbas para el cáncer. He seguido las instrucciones dadas sobre cómo usar estos medicamentos. Sinceramente, durante este tratamiento me estaba volviendo totalmente normal y fuerte hasta que fui a mi país de origen para comprobar mi estado, mi situación actual, todo era completamente normal, completamente saludable y curado.
EliminarSu contacto es;
cureherbal633@gmail.com. o
isespiritualspelltemple@gmail.com
solo el Dr. Puedo recomendar a todos, sinceros y buenos ..
sus medicamentos son muy curativos y efectivos, puros y naturales, sin efectos secundarios
No me bastan las palabras para expresar lo agradecido que estoy estos días. Nunca quise revelar mi identidad, pero debo hacerlo para que quienes viven en la duda y el miedo puedan hacer sus necesidades y tomar decisiones. Quiero agradecer a este maravilloso médico, el Dr. ISE, por su amabilidad incondicional y su apoyo a los pacientes. Me diagnosticaron cáncer el 18 de enero de 2018. He estado en muchos lugares y probé varios tratamientos en vano, leí en las personas testimonios después de usar el Dr. ISE, Herbal, cómo se curaron de Diabetes, Dolores de estómago, Tumol, alergias corporales, VIH, HERPES, VPH, CÁNCER y muchas otras enfermedades e infecciones No estaba convencido porque he pasado mucha gente buscando buscando una cura y demasiado beneficio para mí y me escapé con mi poco dinero duramente ganado hasta que un amigo cercano me contó más sobre el Dr. Ise, cómo su tío, que sufría de VIH y el virus del herpes, se curó después de usar la medicina herbal del Dr. ISE, Inicialmente pensé que era una broma hasta que me ayudó a ordenar medicinas terapéuticas a base de hierbas para el cáncer. He seguido las instrucciones dadas sobre cómo usar estos medicamentos. Sinceramente, durante este tratamiento me estaba volviendo totalmente normal y fuerte hasta que fui a mi país de origen para comprobar mi estado, mi situación actual, todo era completamente normal, completamente saludable y curado.
EliminarSu contacto es;
cureherbal633@gmail.com. o
isespiritualspelltemple@gmail.com
solo el Dr. Puedo recomendar a todos, sinceros y buenos ..
sus medicamentos son muy curativos y efectivos, puros y naturales, sin efectos secundarios
No sé por dónde empezar porque estoy abrumado. Nunca pensé que me curaría del virus del VIH y las verrugas genitales. Estas Enfermedades han afectado mi vida de muchas formas y lo he perdido todo, incluida mi pareja y mi trabajo en el camino de encontrar soluciones a estas enfermedades. Deseo compartir con las personas que viven con el virus del VIH y las verrugas genitales (VPH), y con las que padecen diversas enfermedades, que no se rindan, porque nunca supe que algún día estaré curado y bien. Mi fe volvió después de leer de aquellos que fueron sanados por el Dr. O. Water con sus medicinas a base de hierbas. Me apresuré a contactar a este gran Doctor en drwaterhivcurecentre@gmail.com. Me dio la esperanza de que estaría totalmente curado después del tratamiento, así que hice todo lo que me pidió y me envió sus medicinas a base de hierbas con las instrucciones sobre cómo usarlas. Para mi sorpresa, en la tercera semana, estaba notando grandes cambios en mi sistema corporal y las verrugas desaparecieron por completo, aunque todavía no lo creía hasta que me confirmaron que tanto el VIH como las verrugas genitales eran absolutamente Negativas. Por favor, si vive con alguna enfermedad, le aconsejo que escriba al Dr. O.Water para obtener sus medicamentos. En realidad, es un hombre maravilloso y enviado por Dios, es amable y muy sencillo. Su correo electrónico es DRWATERHIVCURECENTRE@GMAIL.COM. Su Whatsapp es +2349050205019
EliminarDeja que esto te sirva como salvador y amado una vez. Sobre el sagrado corazón digo;
EliminarLas palabras por sí solas no pueden expresar lo satisfecho que me siento en mi corazón por haber sido certificado libre de herpes zoster después de usar los remedios herbales del doctor White. Tenga en cuenta que una persona enferma no quiere castillos, autos o artilugios poderosos, certificados o posición política, simplemente quiere estar saludable. Si todo lo que desea es una cura permanente para esa enfermedad, lo reto a que se comunique con el centro de curación Dr. White en WhatsApp: +2349091844595 o envíe un correo electrónico a / DRWHITETHEHIVHEALER@GMAIL.COM.
(Si un médico dice que siga controlando su condición, entonces obviamente no puede ayudarlo). Cura de hierbas blancas. Solo leí sobre este sanador desinteresado a partir de los testimonios que obtuve de las búsquedas de Google. Lo contacté y me dio su condición para la cura, que seguí estrictamente en 3 semanas y obtuve la certificación de herpes zoster. Deja de manejar esa condición de salud y ponle fin. Deseo que tantos como los que reciban este mensaje se salven. Soy un dejar testimonio para curar de:
VIH/SIDA, Cáncer, hipertensión, Hepatitis A,B,C,D,E. Herpes genital y oral, verrugas genitales y más
#siaoromafaith@gmail.com#
Hola eso es verdad lo que estás diciendo
ResponderEliminarQué gran testimonio me gustaría que todos leyeran y siguieran las instrucciones para curarse de HSV1 y 2. Me diagnosticaron VHS1 y el 2 de marzo de este año y he estado tomando pastillas para prevenir el brote. Nunca dejo de buscar una cura porque creo firmemente que hay algo en algún lugar que puede deshacerse de ella por completo y en agosto de este año, repasé algunos comentarios en Youtube sobre la cura a base de hierbas del Dr. Osato y muchas personas comentaron que tenía la hierbas que pueden eliminar el herpes por completo. Estaba emocionado y me comuniqué con el Dr. Osato y ordené la cura para mí y él me la envió a través de UPS y me dio instrucciones sobre cómo tomarla, que seguí correctamente y he aquí, fui a un chequeo después de dos semanas de tomar las hierbas y mi el resultado muestra NEGATIVO. Mi médico confirmó conmigo que estoy totalmente libre de HSV1 y 2. También puede ponerse en contacto con el Dr. Osato para obtener la cura a base de hierbas de él. Su correo electrónico es osatoherbalcure@gmail.com o WhatsApp él al +2347051705853. El Dr. Osato también tiene la cura para los siguientes virus / enfermedades VIH, VPH, VHS1 y 2, DIABETES, CÁNCER de cualquier tipo, HERPES GENITALES, DOLOR FRÍO ECT. Su sitio web es osatoherbalcure.wordpress.com
EliminarQuiero dar un testimonio sobre mi virus del VIH que fue curado por un gran lanzador de hechizos. Desde los últimos 4 meses he sido paciente con SIDA. Nunca creo que vuelva a vivir mucho y estoy tan agradecido con él, el Dr. Wealthy, que me ayudó a curar mi VIH SIDA las últimas 3 semanas. Me dolía mucho, así que le conté a uno de mis mejores amigos; me dijo que hay un gran lanzador de hechizos que puede curar mi VIRUS. Le pregunté si tenía su correo electrónico, ella me dio su correo electrónico, le envié un correo electrónico, él habló conmigo y él realizó los rituales necesarios y me dijo que después de dos semanas debía ir a una prueba. Lo que hice, cuando el médico me dijo que ahora soy VIH negativo, no me podía creer, fui a ver a otro médico, el resultado seguía siendo el mismo, era humano en el planeta Tierra, así que le envié un correo electrónico y le agradecí. Por favor, si tiene un problema similar, visítelo / póngase en contacto con él en; wealthylovespell@gmail.com o agregarlo en WhatsApp +2348105150446 visite Blog http://wealthyspellhome.over-blog.com TODAS LAS GRACIAS AL Dr. Wealthy ................. GOOGLUCK
ResponderEliminarEste é um testemunho que direi a todos para ouvir. casei-me quatro a quatro anos e, no quinto ano do meu casamento, outra mulher teve um feitiço para tirar meu amante de mim e meu marido me deixou e as crianças e sofremos por dois anos até que eu quis dizer um post em que isso homem Dr. AFRID ajudou alguém e eu decidi tentar fazer com que eu trouxesse meu amor Marido para casa e acredite em mim, acabei de enviar minha foto para ele e a do meu marido e depois de 48 horas, como ele me disse, eu vi um carro entrou em casa e eis que era meu marido e ele veio até mim e às crianças e é por isso que estou feliz em fazer com que todos vocês se pareçam com esse homem e com seu amante de volta a si mesmo. : drafridherbalhome11@gmail.com ou você também pode contatá-lo drafridherbalhome11@gmail.com ..... muito obrigado Dr. AFRID
ResponderEliminar¿Necesita un préstamo o desea refinanciar su hogar, pagar facturas y expandir su negocio? no busque más, sacamos todo tipo de préstamo a una tasa de interés del 3% anual. si está interesado, contáctenos por correo electrónico: johnleemill12345@gmail.com
ResponderEliminarHola amigos .... debe leer ....
ResponderEliminarAM Dr.charles del TEMPLO MISTICO de lAVENDER.
Mi propósito medio de escribir estos, es ayudar en la curación naturalezas habitante, En otra palabra estoy aquí para traer el "bálsamo de Galaad" que ha estado oculto, durante siglos. El "bálsamo de Galaad" simplemente significa HIERBAS que la naturaleza nos ha dado gratuitamente para nuestra curación, aunque muchos no la conocen. Ahora la parte interesante es que toda enfermedad tiene una cura definitiva a base de hierbas, muchos son el olvido de ellos, tengo HIERBAS para STI que la ciencia médica no ha hecho mucho para traer una cura completa como; VIH / SIDA, hepatitis, chancroide, tricomoniasis, papilomavirus humano (VPH) y TRASTORNOS GENITALES, HERPES, GONORREA, CHLAMYDIA ..etc
CUALQUIER enfermedad que usted pueda pensar, la naturaleza tiene una solución definitiva a ella. .. decir un amigo a un amigo
la curación está en cada paso de una puerta,
espero que esto llegue al mundo ancho, y te ruego que encuentres la felicidad eterna y la PAZ en esta encarnación y el ÚNICO que vendrá.
mi dirección de correo electrónico sanctum es hivspelltemple@gmail.com WHATS-APP NUMBER +2348105238925
Los mejores deseos.
GRANDE MAESTRO LAVANDA.
Hello everyone
ResponderEliminarThis is real. I got the herbal product from dr ogbekhilu. which i took for about 19 days, and my ejaculation is now normal and my erection is hard and my penis got bigger than before now 8.5 inches long on erection and off course a very large round. and now i can last long in bed. I am very happy for this Penis Enlargement experience no side effects. You can also get in contact with him on his email :drogbekhiluherbalhome@gmail.com/////////////////////////// Whats app contact:+2348102460821
He can also help with all kinds of cure you may need as follows:1. HIV/AIDS 2. HERPES3. CANCER 4. ALS5. Hepatitis B6. Diabetes7. Weak erection8. Penis enlargement9.Virginal tightening cream
10. If you want a child.
11.If you want your ex back.12 if you always have bad dreams.13 You want to be promoted in your office.14 You want women/men to run after you.15 If you want a child.
que manga de locos por favor!
ResponderEliminar
ResponderEliminarEstoy dando un testimonio sobre el Dr. Tebor, el gran herbolario, él tiene la cura para todo tipo de enfermedades, curó mi virus del herpes simple, aunque visité diferentes sitios web, vi diferentes testimonios sobre diferentes lanzadores de hechizos y herbolarios, pensé : 'Mucha gente tiene la cura del virus del herpes simple, ¿por qué la gente todavía la padece?' Lo pensé, luego me comunico con el Dr. Tebor por correo electrónico, no le creí mucho, solo quería darle una oportunidad, respondió mi correo y necesitaba información sobre mí, luego se los envié, él lo preparó (CURAR) y me lo envió a través del Servicio de mensajería en línea de Airfreight para la entrega, dio mis datos a la Oficina de mensajería, me dijeron que en 2-3 días recibiré el paquete y tomé el medicamento según lo prescrito por él y Fui a chequeo 2 semana después de terminar el medicamento, me dieron negativo en la prueba del virus del herpes simple, si eres paciente del virus del herpes simple hazme un favor contactando con él y le aseguro a todo el que lo esté sufriendo, tu problema nunca quedará. lo mismo otra vez usted se curará. TAMBIÉN DR Tebor ayudó a mi hermana esposo a curar su VIH / SIDA él lo estaba sufriendo durante los últimos 3 años, Después de que él {curara} mi virus del herpes simple, luego mi hermana se enteró, ella fue a casa para contarle a su esposo sobre el Dr. Tebor y luego su esposo le envió un correo electrónico y le explicó su im, también prepara hierbas medicinales y usa el servicio de mensajería de UPS para enviarle las hierbas medicinales y le instruye sobre cómo la usará durante 3 semanas, que en los 15 días de la misma, debe ir a revisarse en el hospital e hizo lo que le indicó el Dr. Tebor a DIOS, sea la gloria que fue la cura de su VIH / SIDA que sufrió durante los últimos 3 años gracias a este gran hombre, estaremos siempre agradecidos con usted, señor, de hecho podría trabajo que hiciste en nuestras familias. Cuando te comuniques con él, asegúrate de decirle que te recomiendo ... contáctalo a través de: Teborherbalcenter@gmail.com O llámalo al +2348106824976
O HAGA CLIC EN SU sitio web: https://teborherbalcanter.wordpress.com
Me diagnosticaron lupus. Todo comenzó una mañana cuando me dirigía al trabajo. Desarrollé una erupción cutánea en la cara, las orejas y los brazos. picaba como loco. Después, me comuniqué con mi médico y me remitieron a un dermatólogo. Se hizo una biopsia y estaba claro que tenía lupus. Me trataron con muchos tipos de medicamentos, incluida prednisona. Estaba confundido sobre qué hacer. Leí un comentario en un Facebook que se curó de la enfermedad del lupus usando medicamentos a base de hierbas. Estaba más que dispuesto a probarlo. Recibí una respuesta del Dr. Ehizele, ordené los medicamentos a base de hierbas. Usé la medicina herbal durante aproximadamente 2 semanas, no he tenido lupus durante más de 2 años. La erupción cutánea de mi cara, orejas y brazos ha desaparecido. ¡Normal! Si padece la enfermedad de lupus. Por favor, pruébalo, estoy disfrutando de la vida y me lo estoy pasando genial viajando. Ha sido asombroso para mi. No te diría esto si no lo hubiera probado yo mismo. Póngase en contacto con el Dr. Ehizele en Gmail (ehizeleherbalhome@gmail.com) visite su página de Instagram en (@dr_ehizele) Llámelo / WhatsApp al +2347089384319 y obtenga ayuda.
ResponderEliminarI can’t believe this is really true I never believe there is cure to this hsv 2 because all the hospital have told me there is no cure to it, few months ago I saw this man email DR.AZIEGBE on internet from a testimony share by someone who he help with his herbal cure I contact his email and ask for his help also, that is how he inform me about the cure process and this man sent me a herbal medicine which I took according to the way he instructed for 2 week I can’t believe when I go for test my result come out negative i am so happy to share this to the world there is real cure to herpes you can also contact DR.AZIEGBE through his email now DRAZIEGBE1SPELLHOME@GMAIL. COM and also WhatsApp him +2349035465208. or my assistant my email: JAMESAVA0001@GMAIL. COM... He also have herbs medicine to cured the following diseases;
ResponderEliminarDiabetes, Lupus, HPV, Gout, Hepatitis A,B, Infertility, HIV/AIDS, CANCER, WART
MI CURA PARA EL VIH POR FAVOR LEA NO IGNORAR Realmente aprecio al Dr. MUSTAFA, mi nombre es CHRIS WINGER. Nunca dejaré de presenciar el DR MUSTAFA. La felicidad es todo lo que veo ahora. Nunca pensé que volvería a curarme del virus del VIH. DR MUSTAFA Llevo 2 años sufriendo una enfermedad fatal (VIH), he gastado mucho dinero yendo de un lugar a otro, de iglesias en iglesias, los hospitales son mi hogar todos los días. Los controles constantes han sido mi pasatiempo fiel no actualizado, vi un testimonio sobre cómo el Dr. MUSTAFA ayudó a alguien a curar su VIRUS del VIH en Internet rápidamente Copié su correo electrónico, que es herbalremedies21@gmail.com / +2347010821863 solo para darle una prueba Hablé con él, me pidió que hiciera algunas cosas que hice, me dijo que me iba a enviar las hierbas curativas, lo cual hizo, luego me pidió que fuera a un chequeo después de unos días, después de usar el remedio herbal. y lo hice, aquí estaba libre de una enfermedad mortal, hasta ahora no más VIH en mí y decidí dar testimonio de este gran hombre llamado DR MUSTAFA en todo el mundo, lo hago fielmente ahora, DR MUSTAFA es cierto si él te gusta HERMANO y HERMANA, MADRE y PADRE es grande, yo le debo a cambio. Si tiene un problema similar, envíele un correo electrónico a herbalremedies21@gmail.com o puede cuál es la aplicación / llamar al +2347010821863 También puede curar estas enfermedades como herpes, diabetes, cáncer, hepatitis A y B, enfermedades crónicas, asma, enfermedades cardíacas, INFECCIÓN EXTERNA, EPILEPSIA, ACV, ESCLEROSIS MÚLTIPLE, NÁUSEAS, VÓMITOS O DIARREA, LUPUS, ECZEMA, DOLOR DE ESPALDA, DOLOR DE ARTICULACIONES. .ETC. Envíe un correo electrónico a herbalremedies21@gmail.com o cuál es la aplicación APP +2347010821863, es un hombre realmente bueno y honesto.
ResponderEliminarQué gran testimonio me gustaría que todos leyeran y siguieran las instrucciones para curarse de HSV1 y 2. Me diagnosticaron VHS1 y el 2 de marzo de este año y he estado tomando pastillas para prevenir el brote. Nunca dejo de buscar una cura porque creo firmemente que hay algo en algún lugar que puede deshacerse de ella por completo y en agosto de este año, repasé algunos comentarios en Youtube sobre la cura a base de hierbas del Dr. Osato y muchas personas comentaron que tenía la hierbas que pueden eliminar el herpes por completo. Estaba emocionado y me comuniqué con el Dr. Osato y ordené la cura para mí y él me la envió a través de UPS y me dio instrucciones sobre cómo tomarla, que seguí correctamente y he aquí, fui a un chequeo después de dos semanas de tomar las hierbas y mi el resultado muestra NEGATIVO. Mi médico confirmó conmigo que estoy totalmente libre de HSV1 y 2. También puede ponerse en contacto con el Dr. Osato para obtener la cura a base de hierbas de él. Su correo electrónico es osatoherbalcure@gmail.com o WhatsApp él al +2347051705853. El Dr. Osato también tiene la cura para los siguientes virus / enfermedades VIH, VPH, VHS1 y 2, DIABETES, CÁNCER de cualquier tipo, HERPES GENITALES, DOLOR FRÍO ECT. Su sitio web es osatoherbalcure.wordpress.com
ResponderEliminardesde finales de 2015 y yo estaba en mi prescripción médico desde entonces, me satisfizo necesitaba para obtener el virus de mi sistema, estaba yendo a través de un blog para encontrar nueva información sobre el Virus del Herpes Simplex me encontré con una revisión de una señora que fue curada por drosasherbalhome@gmailcom me puse en contacto con la base de hierbas y guiaron mwasn't e sobre cómo comprar la fórmula herbal. los productos herbarios me las por 3 semanas que me ayuda a deshacerse del virus totalmente, para una comunicación fácil se puede llegar a DR freeman en su whatsapp +2349035428122
ResponderEliminarSuplementos herbarios han existido durante miles de años y se pueden rastrear durante varias culturas diferentes. En cuanto a ahora. Las hierbas ahora se utilizan para curar el herpes diabético, dolor crónico, regurgitación del asma, dolor de pecho, náuseas, disfagia, hipo, incluso dolor de garganta y ardor de estómago. Me encantan las hierbas. La mayoría de las veces, la inyección y las drogas son sólo una pérdida de tiempo. Me curé de dolor de garganta y enfermedad de la acidez estomacal el año pasado con el uso de hierbas y súper jabón, sufrí de dolor de garganta y ardor de estómago durante 13 años, pero con la ayuda de DR. FREEMAN OSAS hierbas medicina, me curó a las pocas semanas de usar las hierbas y súper jabón que me envió a través del servicio de entrega de DHL. No sé el tipo de problema de salud que se enfrenta en este momento, pero le aseguré que va a ser cura si se pone en contacto con el Dr. FREEMAN OSAS y explicarle su problema, que los problemas se resolverán en pocas semanas, Póngase en contacto con DR FREEMAN OSAS a través de su dirección de correo electrónico: drosasherbalhome@gmail.com o WHATSAP / LLAMle en +2349035428122. compartir las buenas obras del Dr. Freeman Osas y salvar otras vidas de diferentes tipos de infecciones.
ResponderEliminarHace algunos años me hice la prueba de HSV2 positivo y desde entonces he estado tomando diferentes tipos de medicamentos, pero sin mejoría hasta que vi testimonios en Internet de cómo el doctor Isai ha estado curando a diferentes personas de diferentes tipos de enfermedades, inmediatamente. lo contacté. Después de nuestra conversación, preparó el medicamento y me lo envió, que recibí y tomé de acuerdo con sus instrucciones. Ahora mi médico acaba de confirmar mi HSV2 negativo. Mi corazón está tan lleno de alegría, muchas gracias Dr. Isai por curarme. Si estás leyendo esto y padeces VHS o cualquier otra enfermedad, puedes contactar al Dr. Isai en esta dirección de correo electrónico: drisaiherbalcenter@gmail.com o enviarle un whatsapp al +2349034352176. El es un hombre honesto
ResponderEliminarYo soy Marianna. Residente en Alemania, me comuniqué con el virus de la HEPATITIS B de mi madre desde mi infancia y desde entonces comencé a tener síntomas, dolores severos en todos los huesos de la cadera y también a veces vómitos. fue un momento difícil para mí, intenté ver a muchos doctores en busca de ayuda, pero sigo gastando más dinero en diferentes hospitales y nada cambiaba, pero una tarde estaba en la red, estaba revisando el blog de mi hermano, vi un comentario y decidí leer algunos y me sorprendí cuando vi a una señora hablando del Dr. Care. desde Europa me alegré, le envié un mensaje en su correo electrónico, me contó el proceso y me envió el medicamento y cuando recibí el medicamento y lo usé en 2 semanas me diagnosticaron negativo. También descubrí que tiene solución para todas las enfermedades, así que consiga la suya ahora. Envíe un correo electrónico a [drcarevoodoospell@gmail.com] llámelo o whatsApp al +393510620692 para obtener más información
ResponderEliminarTIENE LA CURA PARA LA SIGUIENTE ENFERMEDAD MORTAL
1 VIRUS HERPES
2 Cánceres de tráquea, bronquios, pulmón
3 Infecciones de las vías respiratorias inferiores
4 VIH / VIRUS
5 Enfermedades diarreicas
6 Tuberculosis
7 Diabetes
8 Hipertensión cardíaca
whatsApp al +393510620692 para obtener más información
Yo soy Marianna. Residente en Alemania, me comuniqué con el virus de la HEPATITIS B de mi madre desde mi infancia y desde entonces comencé a tener síntomas, dolores severos en todos los huesos de la cadera y también a veces vómitos. fue un momento difícil para mí, intenté ver a muchos doctores en busca de ayuda, pero sigo gastando más dinero en diferentes hospitales y nada cambiaba, pero una tarde estaba en la red, estaba revisando el blog de mi hermano, vi un comentario y decidí leer algunos y me sorprendí cuando vi a una señora hablando del Dr. Care. desde Europa me alegré, le envié un mensaje en su correo electrónico, me contó el proceso y me envió el medicamento y cuando recibí el medicamento y lo usé en 2 semanas me diagnosticaron negativo. También descubrí que tiene solución para todas las enfermedades, así que consiga la suya ahora. Envíe un correo electrónico a [drcarevoodoospell@gmail.com] llámelo o whatsApp al +393510620692 para obtener más información
ResponderEliminarTIENE LA CURA PARA LA SIGUIENTE ENFERMEDAD MORTAL
1 VIRUS HERPES
2 Cánceres de tráquea, bronquios, pulmón
3 Infecciones de las vías respiratorias inferiores
4 VIH / VIRUS
5 Enfermedades diarreicas
6 Tuberculosis
7 Diabetes
8 Hipertensión cardíaca
whatsApp al +393510620692 para obtener más información
soy Alba residente en madrid españa, he estado sufriendo de herpes durante los últimos 2 años y 5 meses, y desde entonces he estado tomando una serie de tratamientos pero no hubo mejoría hasta que encontré testimonios de DR.CARE de Europa sobre cómo ha estado curando a diferentes personas de diferentes enfermedades en todo el mundo, luego me comuniqué con él también. Después de nuestra conversación, me envió el medicamento que tomé de acuerdo con sus instrucciones. Cuando terminé de tomar la medicina a base de hierbas, fui a un chequeo médico y para mi mayor sorpresa me curé del herpes. Mi corazón está tan lleno de alegría. Si padece herpes o cualquier otra enfermedad, puede comunicarse con DR.CARE hoy en esta dirección de correo electrónico: [drcarevoodoospell@gmail.com] o enviarle un WhatsApp en este número de teléfono +393510620692.
ResponderEliminarTIENE LA CURA PARA LA SIGUIENTE ENFERMEDAD MORTAL
1 VIRUS DE HERPES
2 Cánceres de tráquea, bronquios, pulmón
3 Infecciones de las vías respiratorias inferiores
4 VIH / VIRUS
5 Enfermedades diarreicas
6 Tuberculosis
7 Diabetes
8 Hipertensión cardíaca
WhatsApp él en +393510620692 para más
Soy Marianna, residente en Alemania, me comuniqué con el virus de la HEPATITIS B de mi madre desde mi infancia y desde entonces comencé a tener síntomas, dolores severos en todos los huesos de la cadera y también a veces vómitos. Fue un momento difícil para mí, intenté ver a muchos doctores en busca de ayuda, pero sigo gastando más dinero en diferentes hospitales y nada cambiaba, pero una tarde estaba en la red, estaba revisando el blog de mi hermano, vi un comentario y decidí para leer algunos y me sorprendió cuando vi a una señora hablando del Dr. Care. desde Europa me alegré, le envié un mensaje en su correo electrónico, me contó el proceso y me envió el medicamento y cuando recibí el medicamento y lo usé en 2 semanas, me diagnosticaron negativo. También descubrí que tiene solución para todas las enfermedades, así que consiga la suya ahora. Envíe un correo electrónico a [drcarevoodoospell@gmail.com] llámelo o whatsApp al +393510620692 para obtener más información
ResponderEliminarTIENE LA CURA PARA LA SIGUIENTE ENFERMEDAD MORTAL
1 VIRUS DE HERPES
2 Cánceres de tráquea, bronquios, pulmón
3 Infecciones de las vías respiratorias inferiores
4 VIH / VIRUS
5 Enfermedades diarreicas
6 Tuberculosis
7 Diabetes
8 Hipertensión cardíaca
WhatsApp él en +393510620692 para más
Es un placer para mí escribir este testimonio sobre cómo me curé el herpes genital hace un mes. He estado leyendo muchos comentarios de algunas personas que fueron curadas de varias enfermedades por el Dr. Egbe pero nunca creí que m. Estaba herido y deprimido, así que tenía demasiada curiosidad y quería probar con el Dr. Egbe, luego lo contacté a través de su correo electrónico cuando me comuniqué con él, me aseguró al 100% que me curaría, le supliqué que me ayudara. Mi tratamiento fue un gran éxito, me curó tal como prometió. me envió su medicación y me pidió que fuera a un chequeo después de una semana de tomar la medicación. Estuve de acuerdo con él, tomé este medicamento y fui a un chequeo, para mi mayor sorpresa mi resultado fue negativo después del tratamiento, estoy muy feliz de estar curado y sano nuevamente. He esperado 3 semanas para estar seguro de que estaba completamente curado antes de escribir este testimonio. Hice otro análisis de sangre hace una semana y todavía era herpes negativo. así que supongo que es hora de que recomiendo a cualquier persona que esté pasando por Herpes HSV-1 o HSV-2, VIH, VPH, Hepatitis B, Diabetes, Cáncer que se comunique con él a través del correo electrónico dr.egbeharbalhome@gmail.com O agregue whatsApp +2348051123871
ResponderEliminar¿Qué pasa si ha sido estafado en Internet ?
ResponderEliminarUsted ha sido engañado por bulldozers que están rampantes en ÁFRICA, Francia, en todo el mundo son muy fuertes para usar fotos robadas para tener hombres y mujeres que en realidad están buscando el amor, usted debería haber sido cauteloso para no enviar dinero a alguien que no conoce .
También le invitamos a ponerse en contacto con INFORMACIÓN ESTAFAS (servicio gratuito y llamar de lunes a domingo 24h / 24) si usted es víctima de estafa, hacer un informe en el portal oficial de informes del Ministerio del Interior y Seguridad Pública .
Contáctenos directamente para acceder a nuestro sitio web :
Puede hacer un informe incluso si no ha sufrido una pérdida financiera: puede ser útil para evitar más intentos de estafas.
Correo electrónico : celluleinterpolmondial@rocketmail.com / sitio web : https://signaloipcs.wordpress.com
INFOS URGENT AUX VICTIMES D'ARNAQUES SUR INTERNET
ResponderEliminarVu les nombreuses plaintes sur les forums et témoignages des victimes d’arnaques, nous constatons que ces derniers temps, il y a des victimes tous les jours et nous sommes sûr que d’autres se font avoir et ne disent rien par honte. Il faut absolument que toutes les victimes d’arnaques sur internet portent plainte. En ligne, cela ne prend que 5 minutes et la confirmation de la police Interpol n’est pas compliquée.IL FAUT LE FAIRE… car nous le faisons pour que la police face leur travail et au moins être rembourser les victimes d'arnaques de tout genre sur internet pour un dédommagement qui varie du double au triple selon le montant escroquer par ses fraudeurs . Bien sûr nous serons à l’écoute pour des solutions adéquates.
E-mail : cellule-antifraude@cyberdude.com / cellule.interpolmondial@mail.ru
Estoy asombrado por el remedio de Ohikhobo. He tenido herpes durante más de 6 años con brotes frecuentes. A veces hago un promedio de 2-3 veces al mes. Antes de que pudiera terminar una ruptura, comenzaría la siguiente. Nada me ha ayudado. Me conecté en línea en busca de una posible forma de ver cómo puedo combatir este virus, así que encontré a Ohikhobo aquí en línea después de ver muchos testimonios de cómo curaba el herpes y otras enfermedades con hierbas naturales, así que decidí intentarlo. Tomé su remedio durante dos semanas y me curé por completo. Recomiendo el remedio de Ohikhobo a cualquier persona que sufra de herpes y quiera curarse por completo también.
ResponderEliminarCorreo electrónico: drohikhoboherbalcenter @ gmail com
WhatsApp + 1740-231-2427
El Dr. Osato realmente le ha demostrado al mundo que es real y genuino y que ha utilizado su hazaña a base de hierbas para salvar a muchas personas de HERPES, VIH, VPH, HERPE FRÍO, CÁNCER, DIABETES, etc. Me diagnosticaron herpes y VPH en 2021 y he estado buscando y haciendo preguntas para ver si podía conseguir algo para curar el virus porque no creía lo que dicen los médicos de que aún no se ha encontrado una cura. Encontré un comentario en Youtube y la persona testificó cómo se curó de HSV2 después de usar la medicina herbal del Dr. Osato. Rápidamente contacté al Dr. Osato y le expliqué mi problema y él preparó las hierbas y me las envió a través de UPS y me dio instrucciones sobre cómo usarlas y me dijo que me hiciera un chequeo después de usarlas, lo cual hice después de dos semanas de tomarlas. medicina herbal y mi resultado fue NEGATIVO. Esperé otro mes y me volví a hacer la prueba, el resultado seguía siendo NEGATIVO y mi médico me dijo que estoy completamente libre de herpes y VPH. Estoy muy feliz y agradecida con el Dr. Osato por lo que ha hecho por mí y continuaré compartiendo esto para que la gente sepa que existe una cura para el herpes y el VPH. Puede ponerse en contacto con el Dr. Osato por correo electrónico y WhatsApp para obtener la cura de él. Correo electrónico: osatoherbalcure@gmail.com y WhatsApp +2347051705853. Su sitio web es osatoherbalcure.wordpress.com
ResponderEliminarEstoy tan emocionada de estar libre del virus del herpes de forma permanente con la ayuda de los remedios herbales del Dr. oseigba. Muchas gracias y su medicamento funciona perfectamente sin efectos secundarios. Si está aquí y necesita una cura para cualquier tipo de enfermedad, infección o virus, contáctelo ahora para obtener ayuda en su correo electrónico, droseigba123@gmail.com o what'sAAP +2349019791774 mejor visite su sitio web https://droseigbah123.wixsite.com /droseigbah_herbs
ResponderEliminarBuena suerte 🤞
Estoy aquí para que todos sepan que existe una cura para HERPES 1 y 2. Los médicos han logrado que las personas que viven con herpes sepan que no existe una cura para el herpes y han sido esclavizadas a los antivirales y otras medicinas ortodoxas complementarias solo para ayudar a suprimir el virus y no una cura. Recibí un diagnóstico de herpes 1 y 2 y no creía en mi médico que no había cura para el herpes, sino que investigué en línea y un blogger me presentó al Dr. Osato, un curandero a base de hierbas, que también narró su historia en línea sobre cómo se curó del herpes. después de usar la medicina herbaria del Dr. Osato. Obtuve la medicina herbaria del Dr. Osato y la usé como me indicaron. Fui a la clínica para un chequeo después de dos semanas de usar el producto a base de hierbas. Mi resultado fue Negativo y me programaron otra cita después de 30 días para confirmar mi resultado y la prueba todavía mostró Negativo y me dieron luz verde de que estoy completamente libre de herpes. Todo gracias a Dios por usar a este Gran herbolario para curarme. Puede contactar al Dr. Osato por correo electrónico: osatoherbalcure@gmail.com o WhatsApp +2347051705853. Su sitio web es osatoherbalcure.wordpress.com. He prometido seguir compartiendo mi testimonio, para que la gente sepa que existe una cura para el herpes.
ResponderEliminar